Pose Detection
Pose detection is a new feature of Media Vision Inference API since Tizen 6.5 (C#). This feature provides landmark detection; it defines landmarks and parts of a human body to help detect a human pose with a Motion Capture (MoCap) file, which you can create or edit using various tools.
Background
In Tizen, human body pose landmarks and body parts are defined as follows:
Figure: Definition of human body pose landmarks and body parts
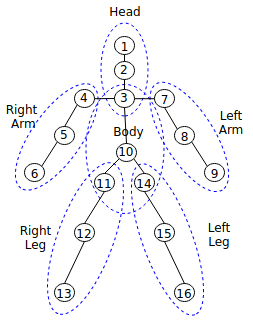
The pose landmark detection models are available in Open Model Zoo such as hosted model zoo or public GitHub site such as public pose model. The public pose models provide landmark information, such as the number of landmarks and locations. To use them correctly, you must map the information to landmarks based on the definition. For example, you can use the public pose model, which provides 14 landmarks as follows:
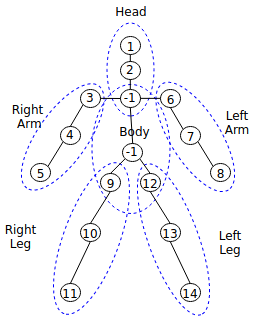 ,
,
In this model, -1 denotes that there are no landmarks. Using this landmark information, you can create a mapping file. Suppose you create a mapping file with the name pose_mapping.txt, then you can populate the pose_mapping.txt file as follows:
angelscript
Copy
1
2
-1
3
4
5
6
7
8
-1
9
10
11
12
13
14
1 denotes that the first landmark of the model corresponds to the first definition, MV_INFERENCE_HUMAN_POSE_HEAD. -1 at the third position denotes that there is no corresponding landmark MV_INFERENCE_HUMAN_POSE_THORAX. 3 at the fourth position denotes that the third landmark of the model corresponds to the fourth, MV_INFERENCE_HUMAN_POSE_RIGHT_SHOULDER. The following table shows how the public model works:
Table: Example of how public pose model maps to the definitions
| Value | Definition | pose_mapping.txt |
|---|---|---|
| 1 | MV_INFERENCE_HUMAN_POSE_HEAD | 1 |
| 2 | MV_INFERENCE_HUMAN_POSE_NECK | 2 |
| 3 | MV_INFERENCE_HUMAN_POSE_THORAX | -1 |
| 4 | MV_INFERENCE_HUMAN_POSE_RIGHT_SHOULDER | 3 |
| 5 | MV_INFERENCE_HUMAN_POSE_RIGHT_ELBOW | 4 |
| 6 | MV_INFERENCE_HUMAN_POSE_RIGHT_WRIST | 5 |
| 7 | MV_INFERENCE_HUMAN_POSE_LEFT_SHOULDER | 6 |
| 8 | MV_INFERENCE_HUMAN_POSE_LEFT_ELBOW | 7 |
| 9 | MV_INFERENCE_HUMAN_POSE_LEFT_WRIST | 8 |
| 10 | MV_INFERENCE_HUMAN_POSE_PELVIS | -1 |
| 11 | MV_INFERENCE_HUMAN_POSE_RIGHT_HIP | 9 |
| 12 | MV_INFERENCE_HUMAN_POSE_RIGHT_KNEE | 10 |
| 13 | MV_INFERENCE_HUMAN_POSE_RIGHT_ANKLE | 11 |
| 14 | MV_INFERENCE_HUMAN_POSE_LEFT_HIP | 12 |
| 15 | MV_INFERENCE_HUMAN_POSE_LEFT_KNEE | 13 |
| 16 | MV_INFERENCE_HUMAN_POSE_LEFT_ANKLE | 14 |
The MoCap file includes the movements of objects or a person. There are various MoCap formats, but a well known BioVision Hierarchy (BVH) file is supported in Media Vision. BVH file has a hierarchy structure to provide landmark information with landmarks’ names, and the structure can be changed. It means that landmark information is different from the definition. To use the BVH file correctly, you have to map the information to the landmarks based on the definitions. For example, the BVH file describes a squat pose as follows:
The example starts with hips and ends with the left foot with 15 landmarks. You can create a mapping file named mocap_mapping.txt as follows:
angelscript
Copy
Hips,10
Neck,2
Head,1
LeftUpArm,7
LeftLowArm,8
LeftHand,9
RightUpArm,4
RightLowArm,5
RightHand,6
LeftUpLeg,14
LeftLowLeg,15
LeftFoot,16
RightUpLeg,11
RightLowLeg,12
RightFoot,13
If there is no mapped landmark, you don’t need to list it. For example, index three is missing. It means that, in this BVH file, the third definition, MV_INFERENCE_HUMAN_POSE_THORAX is not defined and not used.
Prerequisites
To enable your application to use the Media Vision Inference functionality, proceed as follows:
-
Install the NuGet packages for media vision:
C#Copyusing Tizen.Multimedia; using Tizen.Multimedia.Vision; -
Create a structure to store pose data.
For pose detection, use the following BodyPart structure:
C#
Copy
public enum BodyPart
{
Head,
Neck,
RightUpArm,
RightLowArm,
RightHand,
LeftUpArm,
LeftLowArm,
LeftHand,
RightUpLeg,
RightLowLeg,
RightFoot,
LeftUpLeg,
LeftLowLeg,
LeftFoot,
}
Detect human pose
To detect human pose from an image, proceed as follows:
-
Create the source and engine configuration handles:
C#CopypdConfig = new InferenceModelConfiguration(); pdConfig.WeightFilePath = Application.Current.DirectoryInfo.Resource + "model.tflite"; pdConfig.MetadataFilePath = Application.Current.DirectoryInfo.Resource + "model.json"; pdConfig.Backend = InferenceBackendType.TFLite; pdConfig.Device = InferenceTargetDevice.CPU; pdConfig.LoadInferenceModel(); -
Get the image file and fill the MediaVisionSource
sourcewith the decoded raw data. In the following example imagesample.jpg, a person is shown in a squat pose: C#Copy
C#CopyMediaVisionSource source = new MediaVisionSource(rgbframe, width, height, Tizen.Multimedia.ColorSpace.Rgb888); -
To detect landmarks of the pose from the
sample.jpgimage, run aDetectAsyncfrom detector. This will returnLandmark:C#CopyTask<Landmark[,]> taskLandmark = Tizen.Multimedia.Vision.PoseLandmarkDetector.DetectAsync(source, pdConfig); -
Use
Landmarkto get landmarks information from the image: Landmark is a two-dimension array that represents the number of sources for the first dimension and enumBodyPartfor the second dimension:C#Copypublic struct Landmark { /// <summary> /// Represents a location in the 2D space. /// </summary> /// <since_tizen> 9 </since_tizen> public Point Location { get; set; } /// <summary> /// Confidence score of point. /// </summary> /// <since_tizen> 9 </since_tizen> public float Score { get; set; } }
Related information
-
Dependencies
- Tizen 6.5 and Higher
-
API References
- PoseLandmarkDetector class